

新聞の内容は読んでないけどお悔やみ欄のために購読を続けている、という方結構おられると思います。
我が家もほとんどそんな感じです。
その新聞の購読料がだいたい3000~4000円/月と、高いと有名なAdobe製品が買えちゃうレベルです。
というわけで、無料(記事執筆現在)でお悔やみ情報を簡単に手に入れる方法をいくつかご紹介しようと思います。
当初作ろうと思っていたもの
本当はネット上にあるお悔やみ情報を私のサーバー上で取得し、それをメールなりLINEなりで配信する形を考えていました。
しかし、ネット上のお悔やみ情報は(おそらく)個人で運営されており、アクセスされないと運営が成り立たなくなるものでした。
なので以下のような方法をご紹介します。
Google ChromeでWEBページをアプリ化する
Google ChromeはWEBページをアプリを起動するのと同じ操作で見られるようにする機能があります。
PCの場合
まず全国お悔やみ情報メディアさんのWEBサイトからお悔やみ情報を取得したい市や県のページを開きます。
Chromeの右上の「︙」をクリックします。
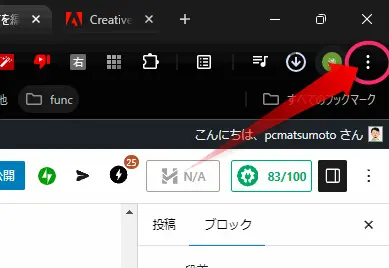
出てきたメニューから「キャスト、保存、共有」→「ページをアプリとしてインストール」をクリックします。
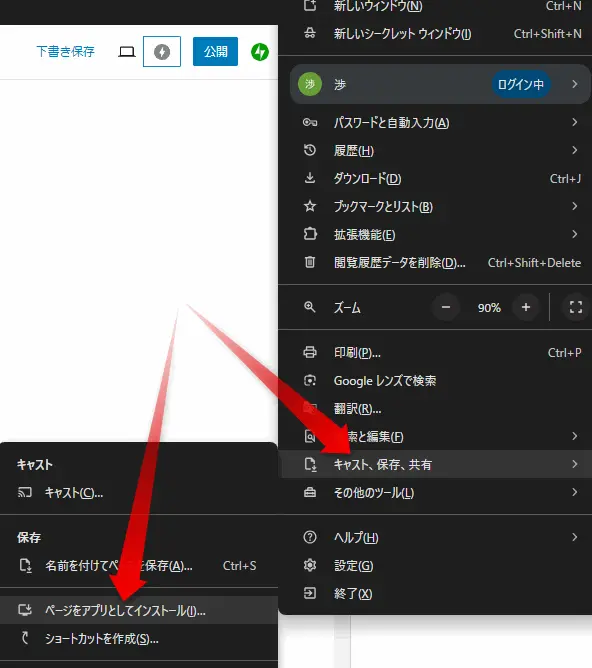
以下のようなウィンドウが出てくるので「インストール」ボタンをクリックします。
すると、アプリのように見えるウィンドウと、デスクトップにアプリの起動アイコンが作成されます。
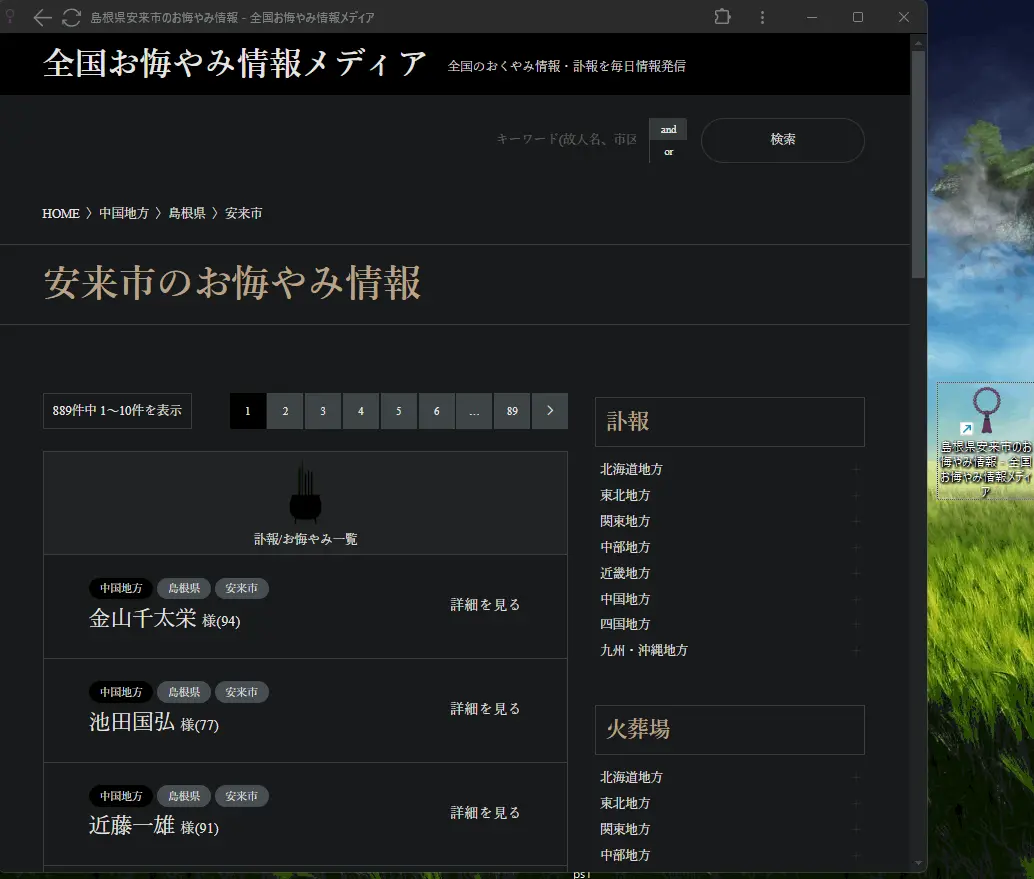
これでアイコンをダブルクリックすればいつでもすぐにお悔やみ情報を確認することができるようになります。
スマホの場合
スマホ版のGoogle Chromeから確認したいWEBページを開き、右上の「︙」をタップ、「ホーム画面に追加」をタップします。
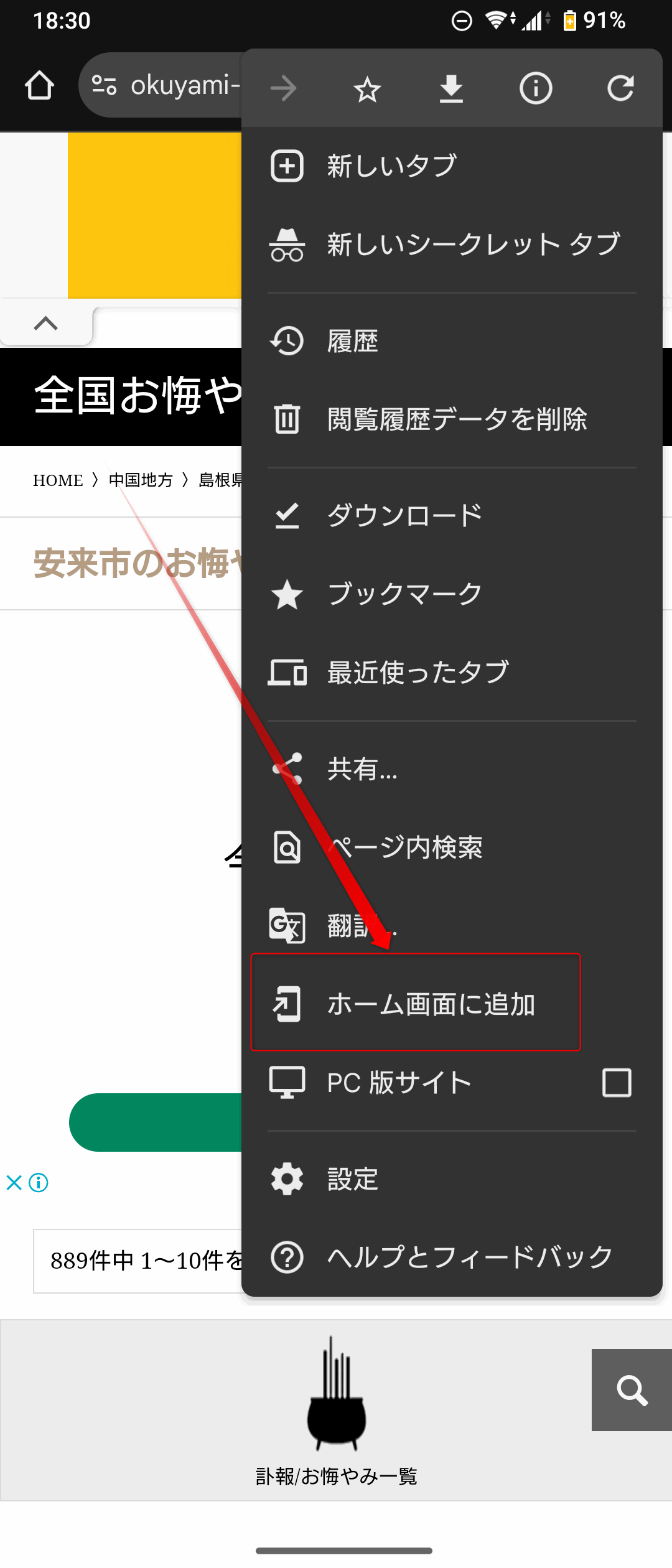
これだけでホーム画面にこのページを開くアプリが追加されます。
Pythonで取得する方法もちょこっと紹介
本来やりたかったことの一部分です。
取得先WEBサイトの禁止事項(自動化された手段(ロボット、ボットネット、スクレーパなど)を使用して本サービスにアクセスする行為)に抵触する可能性があるので、詳細は載せません。
詳細がわかったとしても自動化せずに手動で取得しましょう。
from datetime import datetime
from bs4 import BeautifulSoup
import requests
from requests.exceptions import Timeout
BASE_URL = "https://okuyami-media.com/category/"
REGION = "chugoku-region"
PREFECTURE = "shimane-pref"
CITY = "安来市"
now = datetime.now()
url = f"{BASE_URL}/{REGION}/{PREFECTURE}/{CITY}/?y={now.year}&mon={now.month}&d={now.day}"
try:
res = requests.get(url, timeout=10)
soup = BeautifulSoup(res.text, "html.parser")
elms = soup.find_all("p", class_="name")
for elm in elms:
print(elm.text)
except Timeout:
print("タイムアウトしました。")
except Exception as e:
print(e)まとめ
時代はDX!!


コメント