

世を変えるレベルの画像生成AIが無償配布された?に引き続き、今度は音声認識AIが公開されました。
その名も
Whisperという名前のAIで、音声データ(mp3など)をテキストデータに変換してくれます。
導入方法
公式によると
We used Python 3.9.9 and PyTorch 1.10.1 to train and test our models, but the codebase is expected to be compatible with Python 3.7 or later and recent PyTorch versions. The codebase also depends on a few Python packages, most notably HuggingFace Transformers for their fast tokenizer implementation and ffmpeg-python for reading audio files. The following command will pull and install the latest commit from this repository, along with its Python dependencies
とのことで、簡単に言うと「Python 3.7以降」「最近のPyTorch」「ffmpeg」を使うといいよ!って感じです。
てことで導入していきます。
前提条件
OS
最近のWindows
GPU
最近のNvidia製
Scoop
これはなくてもいいですが、あると様々な開発環境が簡単にインストールでき、面倒な環境変数設定も必要ないのであると便利です。
Windowsユーザーはぜひ使ってみてほしいです。
他にも「Chocolatey」や「winget」などもありますがそこはお好みや環境次第で。
Scoopのインストールは下記のコードをPower Shellから実行するだけです。
Set-ExecutionPolicy RemoteSigned -Scope CurrentUser # Optional: Needed to run a remote script the first time
irm get.scoop.sh | iexPython
開発者はPython 3.9.9を使用したと書いてありましたが、私はPython 3.10.7を使用しました。
特に深い意味はなく、単に最新版だったからです。
インストールは公式Webサイトからインストーラーをダウンロードして諸々を設定、もしくはコマンドラインから
scoop install pythonと入力すればインストール可能です。
Pytorch
「公式サイト」から自分の環境を選択し、「Run this Command:」内のコマンドを入力します。
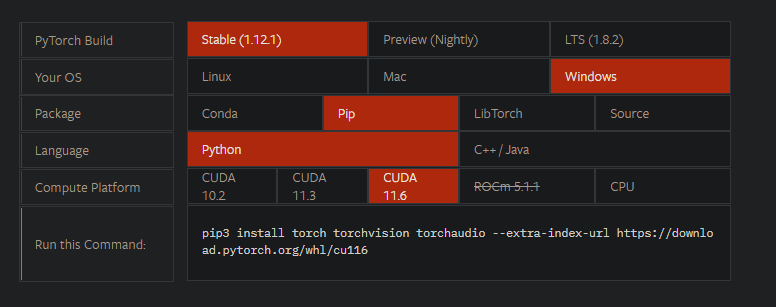
この画像の場合は
pip3 install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu116とコマンドラインから入力すればインストールされます。
CUDA Toolkit
「CUDA Toolkit」を自分の環境に合わせてインストールします。
cuDNN
「cuDNN」をダウンロードします。
登録が必要ですが、簡単なのでちゃちゃっと終わらせましょう。
ZIP形式でダウンロードされるので、どこでもいいので解凍したフォルダを配置し、そのフォルダ内の「bin」フォルダを環境変数に追加します。
ffmpeg
「公式サイト」からダウンロードして環境変数を設定するか、コマンドラインから
scoop install ffmpegなどと入力してインストールしてください。
Whisper
上記までをインストールしてようやく本体のインストールです。
といってもここまで来たらインストールは簡単で、コマンドラインから
pip install git+https://github.com/openai/whisper.gitと入力するだけです。
これでWhisperを使用する環境が整いました。
いざ実行
実はインストールすると2通りの実行方法があります。
コマンドライン
インストールすると「whisper」というコマンドが追加されます。
使用方法は、コマンドラインから
whisper <音声ファイル>と入力するだけ。
デフォルトでは英語の設定となっているので、英語以外の場合は
whisper <音声ファイル> --language <言語>と書いてあります。
が、言語指定しなくても推定してくれます。すごい。
しかも音声ファイルだけでなく動画ファイル(mp4など)を指定してもテキスト化してくれます。すごい。
実行例
最近話題の「CoeFont」さんの「おしゃべりひろゆきメーカー」で試してみました。
題材は夏目漱石の「吾輩は猫である」です。
元の動画はこちら。
変換結果はこちら
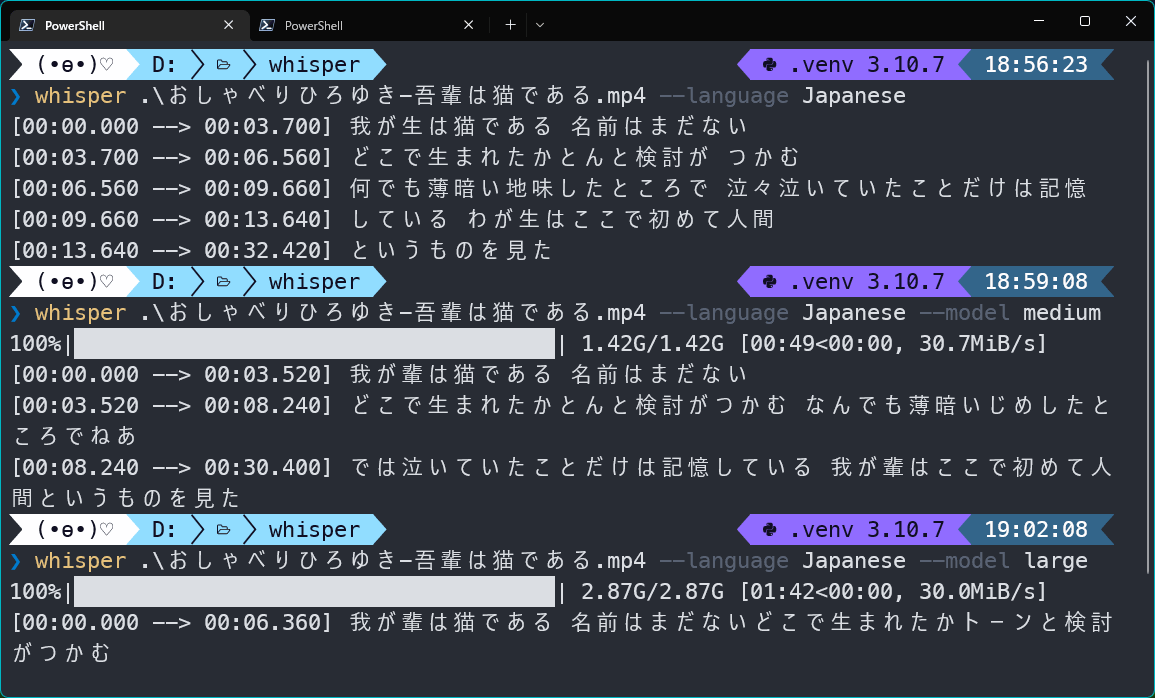
初回起動時には学習モデルのダウンロードがあります。
ダウンロード先は「C:\Users\<ユーザー名>\.cache\whisper」。
「–model」オプションでモデルの指定ができ、サイズやスピードは以下のようになっています。

実行後にフォルダ内に「<入力ファイル>.srt」と「<入力ファイル>.vtt」と「<入力ファイル>.txt」というファイルが出力されます。
後者は文字通り単に音声をテキスト化しただけのものですが、前者は字幕用ファイルで、「何分何秒の時点にこの言葉を発した」というデータです。
このファイルの何がいいかというと、簡単に動画に字幕がつけられることです。
You Tubeなどに字幕ファイルとしてそのままアップロードもできますし、上記したffmpegを使って
ffmpeg -i hoge.mp4 -vf subtitles=hoge.vtt output.mp4などとしてやれば動画に直接字幕を埋め込めます。
Pythonから実行
import whisper
from pprint import pprint
model = whisper.load_model("medium")
result = model.transcribe("おしゃべりひろゆき-吾輩は猫である.mp4", language="Japanese")
pprint(result)こんな感じで使用モデルと入力ファイルと言語を指定して実行するだけです。
返ってくる結果は、
{'language': 'Japanese',
'segments': [{'avg_logprob': -0.22592714608433734,
'compression_ratio': 0.489010989010989,
'end': 3.52,
'id': 0,
'no_speech_prob': 0.03458258882164955,
'seek': 0,
'start': 0.0,
'temperature': 0.0,
'text': '我が輩は猫である 名前はまだない',
'tokens': [50364,
1654,
...
'text': '我が輩は猫である 名前はまだないどこで生まれたかとんと検討がつかむ 何でも薄暗いじめしたところでねあなぁ泣いていたことだけは記憶している '
'わが輩はここで初めて人間というものを見た'}このような「language」「segments」「text」からなる辞書オブジェクトです。
これなら「segments」からvttファイル以外の字幕ファイルも作れるな~と思いますよね?
そのちょっと面倒な作業をやってくれる機能も開発者が用意してくれていました。
今のところ字幕用ファイルの書き出し機能として「write_vtt」「write_srt」という関数が、単なるテキストの書き出し機能として「write_txt」という関数が用意されています(初期のwhisperには含まれていない関数があるので使用する際は最新版をインストールしてください)。
使用方法は
import whisper
from whisper.utils import write_txt, write_vtt, write_srt
model = whisper.load_model("medium")
result = model.transcribe("おしゃべりひろゆき-吾輩は猫である.mp4", language="Japanese")
with open("output.txt", "w", encoding="utf-8") as txt:
write_txt(result["segments"], file=txt)
with open("output.vtt", "w", encoding="utf-8") as vtt:
write_vtt(result["segments"], file=vtt)
with open("output.srt", "w", encoding="utf-8") as srt:
write_srt(result["segments"], file=srt)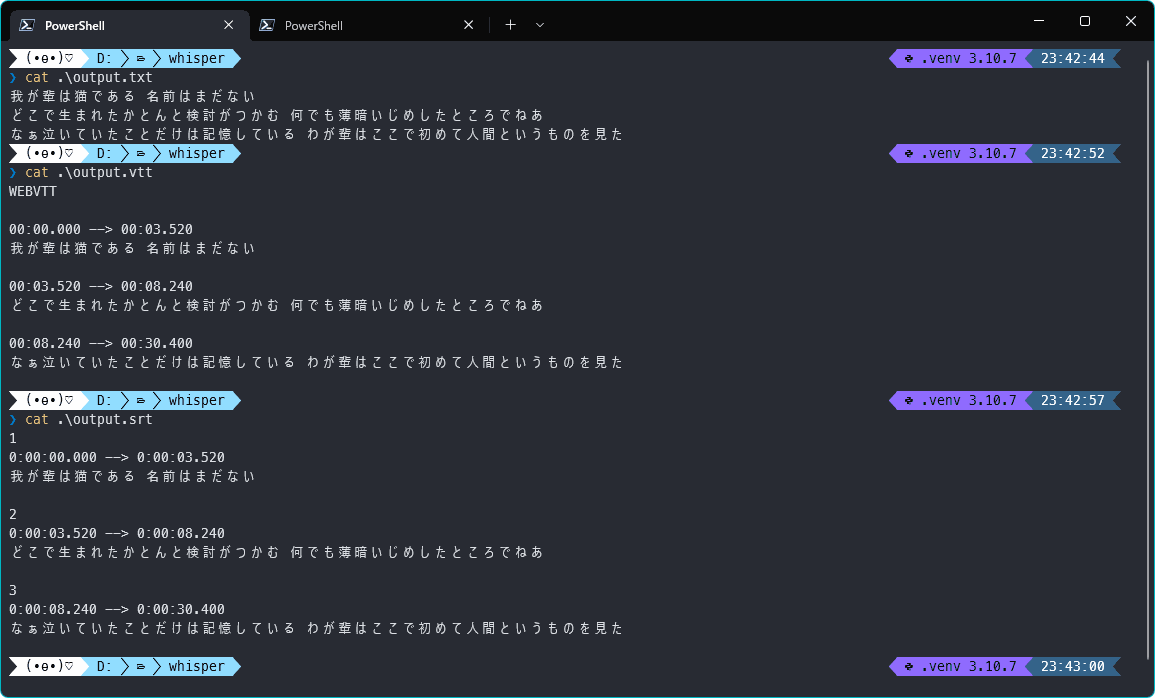
こんな感じで「utils」の関数を呼び出すだけです。簡単!
まとめ
すごいことはすごいAIですが、使い所は限られますね。
正直以前紹介した画像生成AIほどのインパクトはないように感じます。

コメント